Demystifying Big Data Analytics with Apache Spark : Part-2
Spark Architecture, Transformations and Actions
Electronics engineer turned into Sofware Developer🤞On a mission to make Tech concepts easier to the world, Let's see how that works out 😋

Hii Welcome to the second part of my series on Apache Spark! In my previous blog post, we looked into Spark and explained what RDDs are, if you have not read it yet please check out this link Demystifying Big Data Analytics with Apache Spark : Part-1 (hashnode.dev).
Now In this post, we'll take a deep dive into Spark's architecture and explore how it processes data using some basic transformations and actions. Alright, hold on to your hats because things are about to get nerdy!
Spark architecture
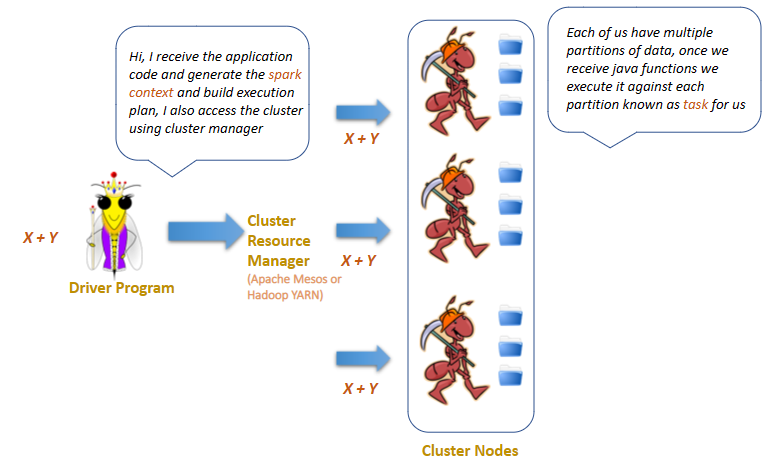
Analogies help us understand and remember new information. So Let's Consider an ant colony as a city with a population of workers, and the queen as the mayor.
The queen ant produces a variety of pheromones, which are chemicals that are used for communication within the colony. These pheromones help to regulate the behavior of the worker ants and coordinate their activities. For example, the queen's pheromones can signal to worker ants to begin foraging for food or to defend the colony from predators.
In this way, the queen ant can be seen as the "director" of the colony, coordinating the activities of the worker ants and ensuring that the colony functions efficiently. Without the queen's guidance, the worker ants would not be able to effectively carry out their tasks and the colony would not be able to survive.
Now from a spark perspective:
Driver program(Queen ant): Responsible for defining the Spark application and initiating its execution. It communicates with the cluster manager to allocate resources across the cluster for the execution of the application.
Executors(Worker ant): Worker nodes that receive tasks from the driver program and execute them in parallel. Each executor runs in its own Java Virtual Machine (JVM) and is responsible for executing one or more tasks assigned to it.
Cluster manager: Responsible for managing the allocation of resources (Apache Mesos or Hadoop YARN )such as CPU, memory to the executors to ensure efficient execution of the Spark application.
Setting Up Workspace
Enough of the theory Now let's get started with hands-on coding.
Prerequisite: Java, JDK,Gradle, Apache-spark
For setting up guide refer following link: Setting up Apache Spark (hashnode.dev)
Hope you have a GitHub account if not please create one and navigate to the following Repo https://github.com/renjitha-blog/apache-spark , copy the GitHub URL and do a git clone of the repo:
Once you have cloned the project to your local open it up in intellij/eclipse as per your choice.
Build.gradle

we have added the above dependencies to get us started with Apache Spark and logging.
Spark Context
SparkContext is the main entry point for interacting with a Spark cluster. It is responsible for coordinating the execution of tasks, distributing data across multiple nodes, and managing the memory and resources of the cluster. The SparkContext is typically created by the driver program and is used to create RDDs
Let us Create a Spark context,

The first line creates a new SparkConf object using the builder pattern. The setAppName method sets the name of the Spark application to "startingSpark", and the setMaster method sets the master URL to "local[]". The "local" part of the URL indicates that the Spark application will run locally on the machine, and the [*] part specifies that the application should use as many worker threads as there are available cores on the machine.
Then new JavaSparkContext object is created, passing in the SparkConf object as a parameter. The JavaSparkContext class provides the main entry point for creating and manipulating RDDs (Resilient Distributed Datasets) in Spark.
Transformations and Actions
Before going ahead I want you to understand two important terms
In the context of Apache Spark, transformations and actions are two types of operations that can be performed on a distributed dataset (RDD).
Transformations are like different machines in the factory that process the candies. For example, one machine might sort the candies by flavor, another machine might group them by size, and a third machine might filter out the ones with certain shapes.
They are operations that create a new RDD from an existing one, by applying some function or transformation to each element of the RDD. Examples of transformations include map(), filter(), and groupByKey(). However, transformations are not immediately executed when they are called. Instead, they create a new RDD. This means that transformations are lazy, meaning they will only be executed when an action is called on the RDD.
Actions in Spark are like the final product of the factory. After processing the candies with the different machines, the factory might package them into bags and label them with their flavors and sizes. Similarly, after processing the data elements with transformations, Spark performs actions to produce final outputs, such as displaying the counting number of elements or saving it to a file.
They are operations that trigger the actual computation of the RDD and return a result to the driver program or write the data to external storage. Examples of actions include count(), collect(), and reduce(). When an action is called on an RDD, Spark evaluates the recipe created by the transformations and returns the computed result to the driver program.
Lambda Functions
To start hands-on coding for Apache Spark, it's important to understand lambda functions in Java. Lambda functions are a way to define small, reusable blocks of code that can be passed as arguments to other methods or functions.
They are especially useful in Spark, which relies heavily on functional programming concepts like map, filter, and reduce. In Spark, you often need to write code that applies a transformation or an action to each element of a distributed dataset (RDD). With lambda functions, you can define the logic for that operation in a concise and readable way. For example, you can use a lambda function to map a list of integers to their squares like this:
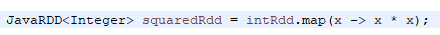
Here, the map method takes a lambda function that multiplies each element x by itself (x -> x * x). This returns a new RDD that contains the squares of the original numbers. For learning more about lambda expression refer to the following website: https://hevodata.com/learn/java-lambda-expressions/ .
Creating RDD
RDDs can be created in two ways: either by parallelizing an existing collection in the driver program, or by referencing a dataset in an external storage system like HDFS, HBase, or any other data source that provides a Hadoop InputFormat.
Let's say you have data which is a set of integers and you want to create RDD below are the 2 ways, one is parallelizing as below:

Another way is referencing a dataset, below I am loading a text file using sc.textFile() method and then applying the flatMap transformation to it.
In the lambda expression passed to flatMap, each line of the text file is split by a comma (,) and converted into a list of integers using a loop that iterates over each string element in the line. Finally, the list is returned as an iterator that contains the data:
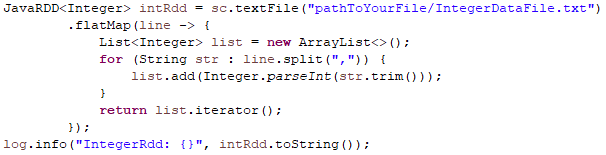
As you might have noticed while logging intRdd , the result might not have been the integer array you expected it would have been as below:
IntegerRdd: MapPartitionsRDD[2] at flatMap
This is because MapPartitionsRDD[2] is a type of RDD that is generated when you apply a transformation that involves modifying or mapping the partitions of the original RDD. It's an internal representation of an RDD in Spark, which means that you won't be able to see the actual values of the RDD by simply printing it to the console.
If you want to see the values of a MapPartitionsRDD, you can use the collect() action to retrieve all the elements of the RDD and then print them to the console. However, be aware that if the RDD is very large, this can be inefficient or even cause your program to run out of memory. Changing it to below will help you see the array of the integers.

Performing Transformations
Now let's perform a few transformations on the data:
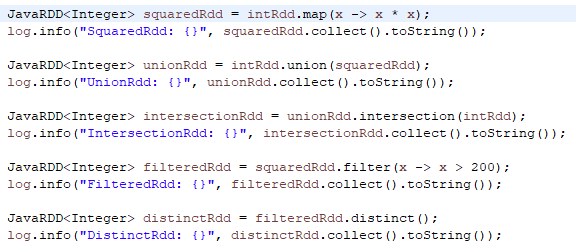
map() - takes an RDD of integers called intRdd and uses the function to create a new RDD called squaredRdd, where each element is the square of the corresponding element in intRdd.
union() - create an RDD called unionRdd by combining intRdd and squaredRdd.
intersection()- create an RDD that contains only the elements that are common to both unionRdd and intRdd.
filter()- create an RDD that contains only the elements of squaredRdd that are greater than 200.
distinct()- create an RDD that contains only the unique elements of filteredRdd.
It would give results like the below:

Performing Actions
If you have noticed in the above code, all tramsformation were resulting in an intermediate JavaRDD<Integer> object, meaning no actual computation occurred, now to perform some computations we need to tell spark to perform some actions on these RDDs like below:

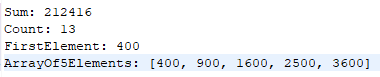
reduce() -calculates the sum of all the integers in the RDD, This function is applied to all elements in the RDD until there is only one value left, which is the sum of all the integers.
count() -calculates the number of elements in the RDD
take()- takes an integer argument and returns an array of that many elements from the beginning of the RDD.
first()- returns the first element in the RDD.
Giving you similar results:
Hurray you have completed your first hands-on coding in Apache Spark, Kudos to you for your perseverance :)
Now, here we only covered very few transformations and actions, to know all available methods you can visit the apache spark documentation.
https://spark.apache.org/docs/latest/rdd-programming-guide.html#transformations
Keep up the good work let's meet in the next part of this series!! Meanwhile i would love to know your feedback/comments or if you want me to write on any specific topics do let me know :)