Demystifying Big Data Analytics with Apache Spark : Part-1
Basics of Apache Spark and RDD


Posted by Renjitha K in Renjitha K's Blog on Mar 25, 2023 2:27:13 PM

As the amount of data generated by individuals and businesses continue to grow exponentially, the need for technologies like Apache Spark that can process and analyze large datasets efficiently becomes even more crucial.
I am planning to create a series of content on ApacheSpark starting from basics so stay patient if you don't see architecture/hands-on coding immediately, join me in this learning process and let's learn together what this is all about.
What is Apache Spark ?
Apache Spark is an open-source big data processing engine that is designed to be fast, flexible, and easy to use. It s a parallel execution framework that enables us to perform operations on big data sets. It was created at UC Berkeley in 2009 and has since become one of the most popular big data processing frameworks in use today.
But we already have frameworks like Hadoop, then why Apache Spark?
You may have heard of Hadoop before. There is still a lot of interest in this parallel execution framework that utilizes the map-reduce technique for crunching large data sets. Now if you do not understand the word MapReduce which I am going to use quite often in this series, Please check out my blog on MapReduce: https://renjithak.hashnode.dev/understanding-mapreduce-a-beginners-guide
Now getting back, The technology was revolutionary, but it has two drawbacks. The model is very rigid, to begin with, an initial map must be drawn and then a reduced process must be created, which is powerful, but not suitable for every requirement.
Another Challenge would be that if you have complex requirements, then you need to chain together, map-reduce jobs, and due to the way that Hadoop map produce is designed after one map produces, the results have to be written to disk and then reloaded into the next map task. So there's quite a hit on performance there.
Spark executes much faster by caching data in memory across multiple parallel operations, whereas MapReduce involves more reading and writing from disk.
So speed is one thing, but how else is Spark different from Hadoop?
To Understand that I want to give you a background on RDD,
RDD stands for Resilient Distributed Datasets, They are essentially an immutable collection of schemaless objects that are partitioned across multiple nodes in a cluster and can be operated in parallel. You can think it of as a way to represent and manipulate data in a distributed and fault-tolerant manner.
Ohh Now, what is immutability and how does it help?

Well, any object that's once constructed if it cannot change its state you can consider it to be immutable. But what is the advantage here? Refer to the image below.
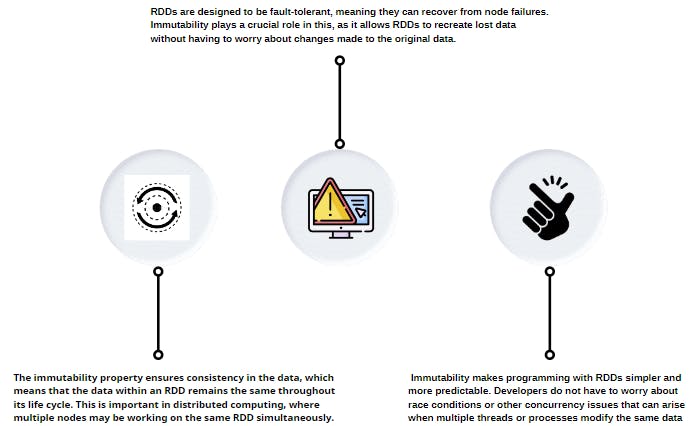
Coming back, An interesting feature of Spark is that it does something called Lazy evaluation, rather than just doing things sequentially, it builds something called an execution plan. Where in a graph representing the work that we want to do is built and only when we're ready to get the data results that we want will spark actually run that execution plan.
But what is the big deal about that?
This would enable the same to perform clever optimizations, such as it can spot the two parts of your process that are not dependent on each other. Therefore, Spark can decide to run those two parts in parallel in runtime without any code handling.
Some of the most powerful features of Spark is its ability to perform complex data transformations and analytics using a set of high-level APIs, we can use combinations of not just maps and reduces, but also operations such as salts, filters and joins as well, meaning that we have a much richer set of tools than just map reduce.
But isn't this similar to streaming and processing data, which I can achieve through Kafka streams as well?
Spark Streaming receives live input data streams which can be through kafka or other resources, it collects data for some time, builds RDD, and divides the data into micro-batches, which are then processed by the Spark engine to generate the final stream of results in micro-batches. Making it very easy for developers to use a single framework to satisfy all the processing needs. It can handle a variety of data processing workloads, including batch processing, stream processing, machine learning, and graph processing.
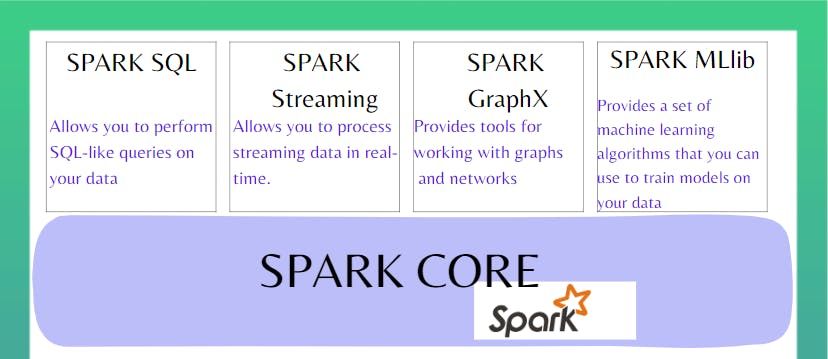
Apache Kafka is a distributed streaming platform that is designed for building real-time, data-intensive applications. It is primarily used for processing and managing streams of data, such as log files, application metrics, and user interactions.
While Apache Kafka and Apache Spark are different technologies, they are often used together to build end-to-end data processing pipelines.
I hope you could get a basic idea of Apache spark, let me know your feedback/comments, let's indulge more into the architecture in coming blogs and learn together!! :)