Understanding MapReduce: A Beginners Guide
Electronics engineer turned into Sofware Developer🤞On a mission to make Tech concepts easier to the world, Let's see how that works out 😋

Most of us have been hearing the term MapReduce for a long while now, I have been wondering what this term means, Let's try to understand the basics of the same.
So, MapReduce is a powerful programming model and software framework for processing large amounts of data in a distributed computing environment. The MapReduce framework allows for the processing of vast amounts of data in parallel across multiple nodes. It is particularly useful for big data applications where traditional methods of data processing are not feasible. It was first introduced by Google in 2004 to handle the large-scale data processing requirements of its search engine.
Prior to the introduction of MapReduce, parallel and distributed processing was typically done using a combination of low-level APIs and libraries. Developers had to write custom code to handle the distribution of data and processing across multiple nodes, which was often complicated and error-prone.
Let's have a walkthrough on a use case on how traditional approaches used to work

Suppose you work for a financial services firm that manages investment portfolios for a large number of clients. The firm maintains a database of all transactions related to these portfolios, including details such as the client name, the date of the transaction, the type of asset involved, and the transaction amount and you want to identify the highest transaction amount for a particular client.
In general, you can,
Split the dataset into smaller chunks based on the client name or date and distribute the data across multiple machines.
Each machine can then process the data for its assigned clients or dates and identify the highest transaction amount.
Once all the machines have processed their respective chunks of data, the results can be aggregated to identify the client with the highest transaction amount.
Let us now understand the challenges associated with this traditional approach
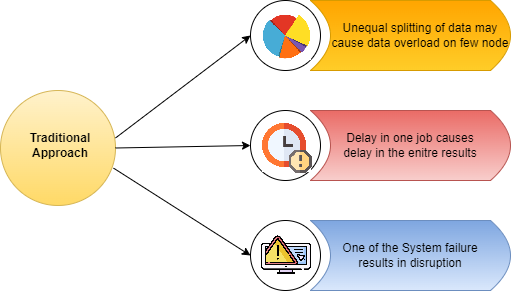
To begin with is the Critical path problem, which involves ensuring that the job is completed on time without delaying the next milestone or actual completion date. If any of the machines working on the task experience a delay, the entire work schedule gets delayed.
Another challenge is the Reliability problem, which arises when one or more machines working with a part of the data fail. Managing the failover process becomes a challenge, as it is essential to ensure that the overall system remains functional.
Splitting the data into smaller chunks that can be distributed evenly among the machines is also a challenge. There is a need to ensure that each machine receives an equal part of the data to work with, to prevent overload or underutilization of any single machine.
Additionally, the system must have a fault tolerance capability to ensure that the failure of any Single Machine does not cause the entire system to fail.
To overcome these challenges, new programming models and frameworks such as MapReduce, Apache Spark, and others have emerged. These frameworks provide a more user-friendly and scalable approach to distributed computing while addressing the challenges associated with traditional parallel and distributed processing.
But What is MapReduce?
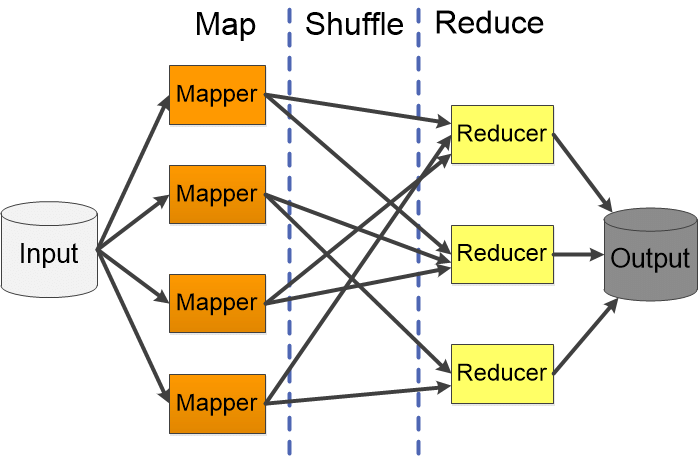
In MapReduce, a job is split among multiple nodes and each node works on a part of the job simultaneously. So, the MapReduce method relies on the Divide and Conquer paradigm which helps us to process the data across multiple machines. As the data is processed by multiple machines instead of a single machine in parallel, the time taken to process the data gets reduced by a tremendous amount. It mainly has two distinct tasks Map and Reduce.
Map Phase: This is where you turn your input data into key-value pairs. Multiple nodes run the map phase simultaneously, so large datasets can be processed efficiently.
Reduce Phase: Here, the key-value pairs created in the map phase are aggregated and combined. The reduce phase also runs parallel across multiple nodes like the map phase.
The MapReduce framework also includes a Shuffle and Sort phase, which is responsible for sorting and shuffling the intermediate key-value pairs produced in the map phase. This is what allows the reduce phase to efficiently process the data.
A Credit Card Transaction Example of MapReduce
Suppose you work in a bank that has a large database of credit card transactions in a file Products.txt and the data in it as given below, and you want to identify the count of frequently purchased items by the customers.
Laptop, Chair, Fridge, Book, Laptop, Fridge, Fridge, Chair, Laptop
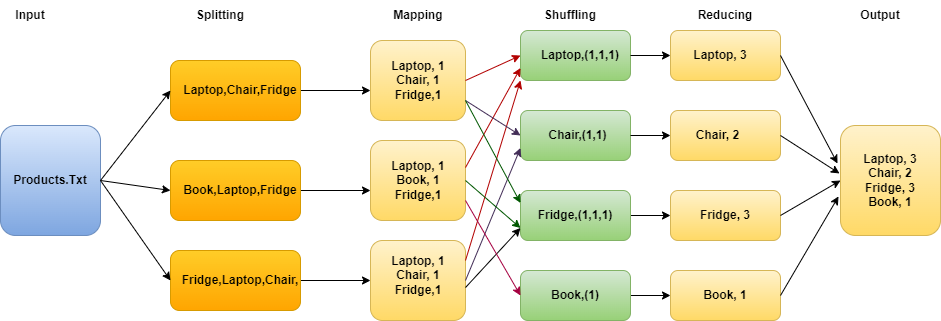
Here we will try to find the unique products and their occurrences.
To begin with, the Input data (Products.txt) is split into 3 smaller chunks and distributed across multiple nodes.
In the mapping phase, we tokenize the words inside each mapper and assign a value (1), since each word in itself will occur once.
Next, a list of (key, value) pairs are generated with the product names and (1) as the value.
Post this, sorting and shuffling are done to send all the tuples with the same key to the reducer.
After this phase, each reducer will have a unique key and list of values corresponding to the key eg: Fridge,[1,1,1]; Chair,[1].
Now each reducer sums up the value in the list for each key and produces a result.
Finally, all output (key, value) pairs are written into an output file.
This approach using MapReduce can help the bank to quickly process a large dataset and extract valuable insights and can be used to inform marketing campaigns or to negotiate deals with retailers selling those items, without overwhelming a single machine.
Let's look at some of the Advantages of this approach
MapReduce provides an obvious advantage in Parallel processing by splitting the data into smaller parts and processing them in parallel across multiple machines, this helps in achieving significant speedups compared to traditional serial processing methods
Data locality is another key advantage, which is achieved by scheduling tasks on the same node where the required data is already stored. Instead of transferring data over the network from a different node, MapReduce assigns tasks to worker nodes that already have the necessary data in their local file system or memory.
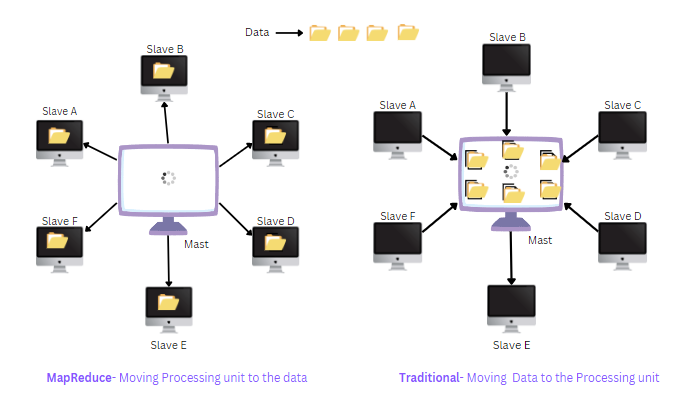
To start a MapReduce job, the input data is divided into blocks and stored on different nodes in the Hadoop Distributed File System (HDFS). When a mapper task is scheduled, it is assigned to a node that has a copy of the input data block required for processing. This allows the mapper to read the data from the local disk or memory wherein it:
Reduces network traffic
Minimizes data transfer time
Improves the performance of MapReduce jobs
Hope you got a basic understanding of the ever confusing word MapReduce through this blog, looking forward for your Feedback/comments. Happy Learning!!